The Escalation Process
CDATHub events are controlled and monitored
by a set of escalation functions which alert maintenance
personnel of the events. In general there are two methods email
and instant messaging. Email is intended to contain the full
register of information on the event to resolve the issue.
Instant messaging through the shell process is intended to send
short messages to personnel to get their attention.
The diagram below depicts the functions of
the alert process. All functions revolve around the event
counter. It is an array of all possible errors and
notifications. The event counter provides the data for the rate
detection functions and count threshold functions.
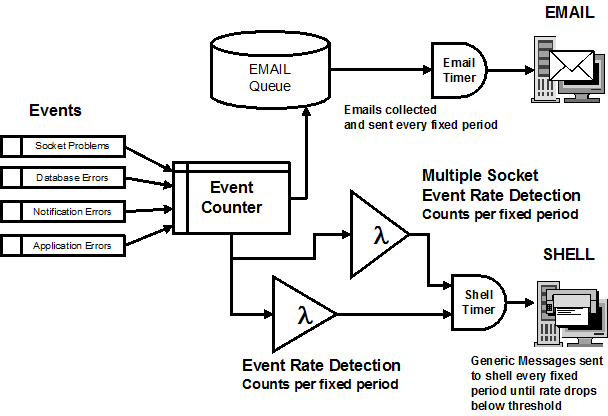
Notifications (rule based messages) and
Errors (application based messages) are subject to a two stage
alert process. These events are sent to the email server in the
first stage and then to a shell process in the escalation.
At all times, events are explicitly recorded and sent to the
email server for inspection.
Notifications and Errors are treated
differently when deciding when to create an alert.
Notifications:
Notifications are associated with
the sockets connected to CDATServers. For this reason the alert
parameters are attached to the CDATServer table which is a list
of all the sockets. Notifications are governed by EmailEnabled (Y/N),
NoEvents, EmailPeriod(in
seconds) as shown below for the socket connected to _CENTRALServer
(a CDATServer).
CDATServer
|
Description |
Active |
Store |
Address |
Port |
NoPair1 |
EmailEnabled |
NoEvents |
EmailPeriod |
ShellEnabled |
ShellPeriod |
|
_CENTRALServer |
Y |
Y |
192.168.0.78 |
8000 |
1 |
Y |
10 |
600 |
Y |
300 |
The initial notification events in this
case are sent immediately via email
(if enabled Y, yes in this example) up to a fixed count (10). The count is reset every 24 hours.
If the count is exceeded in flooding then the timer (600
seconds) will determine how often the email is sent.
The email Notification alert is set for
each input socket. Each can be different.
The counters are reset every 24 hours and
the time of reset is displayed in the configuration tab as shown
below.
Notification Escalation:
The escalation to the shell process
is independently determined by the rate array. It monitors all
notifications and the rate attached to a socket. If
Notifications exceed a global rate then a shell process
is created. The global rate threshold is created with two
variables ShellPeriodNotifyRate (600 seconds) and ShellRateNotifyThreshold (3) as shown in the example below.
StartUp
|
Key_Description |
Key_Data |
Description |
|
ShellPeriodNotifyRate |
600 |
The number of seconds to measure the number of
notifications occurring. This is the rate
(counts/period) |
|
ShellRateNotifyThreshold |
3 |
The threshold of the number of notify events in the
period. This is the rate (counts/period) threshold. A
higher rate generates a shell process. |
The escalation process itself may generate
large numbers of shell process. This is highly undesirable if
the alert process is a pager or SMS message. Therefore the shell
process is limited by the shell period in the CDATServer table.
Multiple Notification on more than one
socket Escalation:
There is a test for notifications on
multiple sites at the same time. In this test if more than one
socket is having notification problems then there may be a
larger problem and so an alert is generated to on Notification
ErrorCode 10. This is hard coded. The shell timer to stop
flooding from this alert is also hard coded to the timers for
socket [0] the CDATServer at the top of the table.
Errors:
Errors are not necessarily
associated to any devices as they can exist for any part of the
application. So global email parameters for errors are located
in the StartUp table and the ErrorCodes table.
The initial error events are sent immediately via email
server up to a fixed count (EC_NoEvents). The count is reset every 24 hours.
If the count is exceeded in flooding then the timer (EC_EmailPeriod)
will determine how often the email is sent.
StartUp
|
Key_Description |
Key_Data |
Description |
|
EC_EmailPeriod |
600 |
Time in seconds between emails |
|
EC_NoEvents |
10 |
Number of events before the email period is active |
Error
Escalation:
The escalation to the shell process
is independently determined by the rate array. It monitors all
errors and the rate attached to a socket. If Errors exceed a global rate
then a shell process is created. The global rate
threshold is created with two variables ShellPeriodErrorRate
(590 seconds) and ShellRateErrorThreshold (2) as shown in
the example below.

